
 EN
ENCORPORART_GRAMM_PT_1.1
Gramática Semântica WordSketch para o CORPORART – Expressões em CQL para extração de relações semânticas entre nomes, verbos e adjetivos
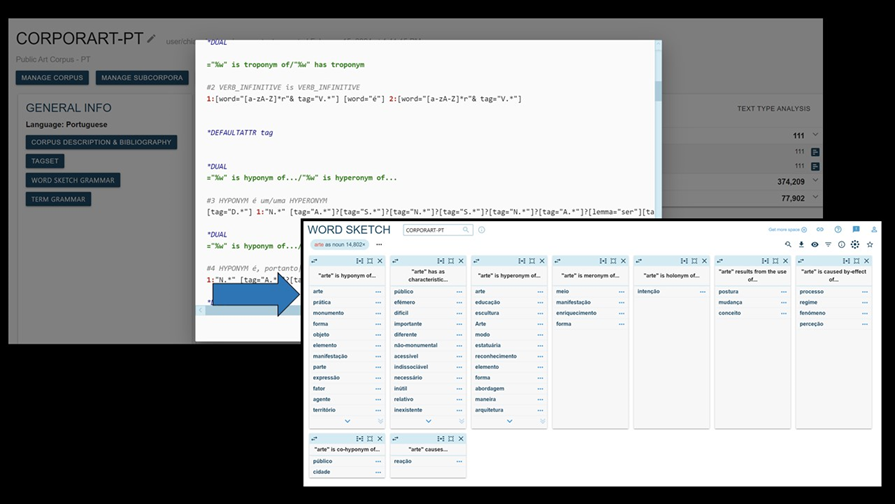
Figura 1: O WordSketch que resulta da aplicação da CORPORART_GRAMM_PT_1.1 no CORPORART_PT
Descrição
A CORPORART_GRAMM_PT_1.1 é uma gramática semântica para o Português Europeu, codificada em linguagem Corpus Query Language (CQL) para o Sketch Engine. É constituída por 39 padrões léxico-conceptuais desenhados para a extração semiautomática de itens lexicais semanticamente próximos. Abrange múltiplas relações semânticas, como a hiperonímia/hiponímia, troponímia, holonímia/meronímia, mas também relações essenciais para a descrição de eventos (e.g., agente/resultado, instrumento, localização etc.) e para a descrição de adjetivos (e.g., caraterização).
Tipicamente, as gramáticas do Sketch Engine são utilizadas para extrair e categorizar colocações de acordo com as relações gramaticais que apresentam. A contribuição que esta gramática aporta é, precisamente, o facto de ter sido desenhada para a recuperação de informação semântica, e não estritamente sintagmática.
A gramática CQL atua com base numa palavra-chave e o resultado é exibido na forma de um Word Sketch. Apesar de a CORPORART_GRAMM_PT_1.1 ter sido pensada para o CORPORART, poderá ser aplicada a qualquer outro corpus em Português Europeu.
Mais sobre esta gramática
Barbero, C. (2024). ArtNet: para um modelo de integração de léxico de especialidade numa rede relacional de léxico comum, PhD dissertation, NOVA University Lisbon (forth.).
Barbero, C. (2022). CQL Grammars for Lexical and Semantic Information Extraction for Portuguese and Italian. In: Pinheiro, V., et al. Computational Processing of the Portuguese Language. PROPOR 2022. Lecture Notes in Computer Science, vol 13208. Springer, Cham. https://doi.org/10.1007/978-3-030-98305-5_35
Identificador
DOI: https://doi.org/10.34619/j2xi-fxfo
ACESSO
A CORPORART_GRAMM_PT_1.1 é de livre acesso, de acordo com as atuais políticas de Open Access e está disponível aqui.
Autoria e Afiliação
A CORPORART_GRAMM_PT_1.1 foi concebida por Chiara Barbero e Professora Raquel Amaro no âmbito do programa de Doutoramento em Linguística de Chiara Barbero e da bolsa PD/BD/128131/2016. Este trabalho foi, também, financiado por fundos nacionais através da FCT – Fundação para a Ciência e Tecnologia, I.P., no âmbito do projeto UIDB/LIN/03213/2020; 10.54499/UIDB/03213/2020 e UIDP/LIN/03213/2020; 10.54499/UIDP/03213/2020 – Centro de Linguística da Universidade NOVA de Lisboa.
Como citar
Barbero, Chiara & Amaro, Raquel (2024). #CORPORART_GRAMM_PT_1.1: a semantic Word Sketch Grammar for #European Portuguese, DOI: https://doi.org/10.34619/j2xi-#fxfo